These study notes are for the Open Data lecture by Oleg Lavrovsky at the Berne University of Applied Sciences Certificate of Advanced Studies in Data Analysis program.
The course of study is designed for professionals interested in data projects and needing to know more about data analysis. The intent of this lecture is to present a practitioner perspective as well as some introductory background on open data, the open data movement, and several real-world projects - with details of the data involved, legal conditions and technical challenges.
The notes begin with an introductory Part 1 below, and continue with a deep-dive on the open data lifecycle in Part 2.
1. Introduction
It is said: attention is in short supply in our information overloaded society. If we break this statement down to its foundations, we may wish to focus on the question of: how accessible are the constituent components of knowledge, which allow us to focus our attention appropriately? The relationship could be described by a simple graph:
Attention -> [ Data -> Information -> Use ] -> Knowledge
Data is only put to use when there is the possibility of change in the information. (In other words: “where there is perfect certainty, there is no information: There is nothing to be said.” - from a recent Nautilus article on Claude Schannon). Cycles of transforming data to useful information, lead us to knowledge.
The open data community, exemplified by the Open Knowledge network, is concerned with sustainable access in each of these domains. It is my belief that the value of data analysis grows in correlation with the number of degrees of openness (i.e. openness to fellow experts, to colleagues, the wider organization, fellow citizens, …) that are supported.
Definitions
Let us more precisely define the concept of Data as:
da•ta (dāˈtə, dătˈə, däˈtə)
- n. Factual information, especially information organized
for analysis or used to reason or make decisions.
- n. Computer Science Numerical or other information represented
in a form suitable for processing by computer.
- n. Values derived from scientific experiments.
The concept of Open will be defined for our purposes as follows:
“A piece of content or data is open if anyone is free to use,
reuse, and redistribute it - subject only, at most, to the
requirement to attribute and share-alike."
Open Data is about open…
- File formats, e.g. CSV
- Licenses, e.g. ODC-BY
- Schemata, e.g. Data Packages
- Catalogues, e.g. CKAN
- Tools, e.g. GoodTables
- Communities, e.g. Opendata.ch
In Switzerland
Das Thema Open Data bewegt eine grosse Vielfalt von Akteuren in Behörden, Medien, Firmen und der wachsenden Schweizer Community einzelner Entwickler, Designer und Aktivisten. Die Dynamik ist da, der politische Wille entsteht, den Austausch findet statt.
(adapted from make.opendata.ch)
Here are some ‘Classic’ Swiss online data sources:
- Government (BFS)
- Geography (GeoAdmin)
- Science (CERN)
- …
The new Swiss Open Government Data platform, opendata.swiss, pulls numerous official datasets into one place:

–Screenshot of opendata.swiss
Such portals build upon the experience of numerous community projects and prior efforts to organize information online relevant to a diverse user base. The main function is to make important metadata - such as time of update, terms of use, ownership, typology, schema - available in one place, searchable and cross-referenceable.
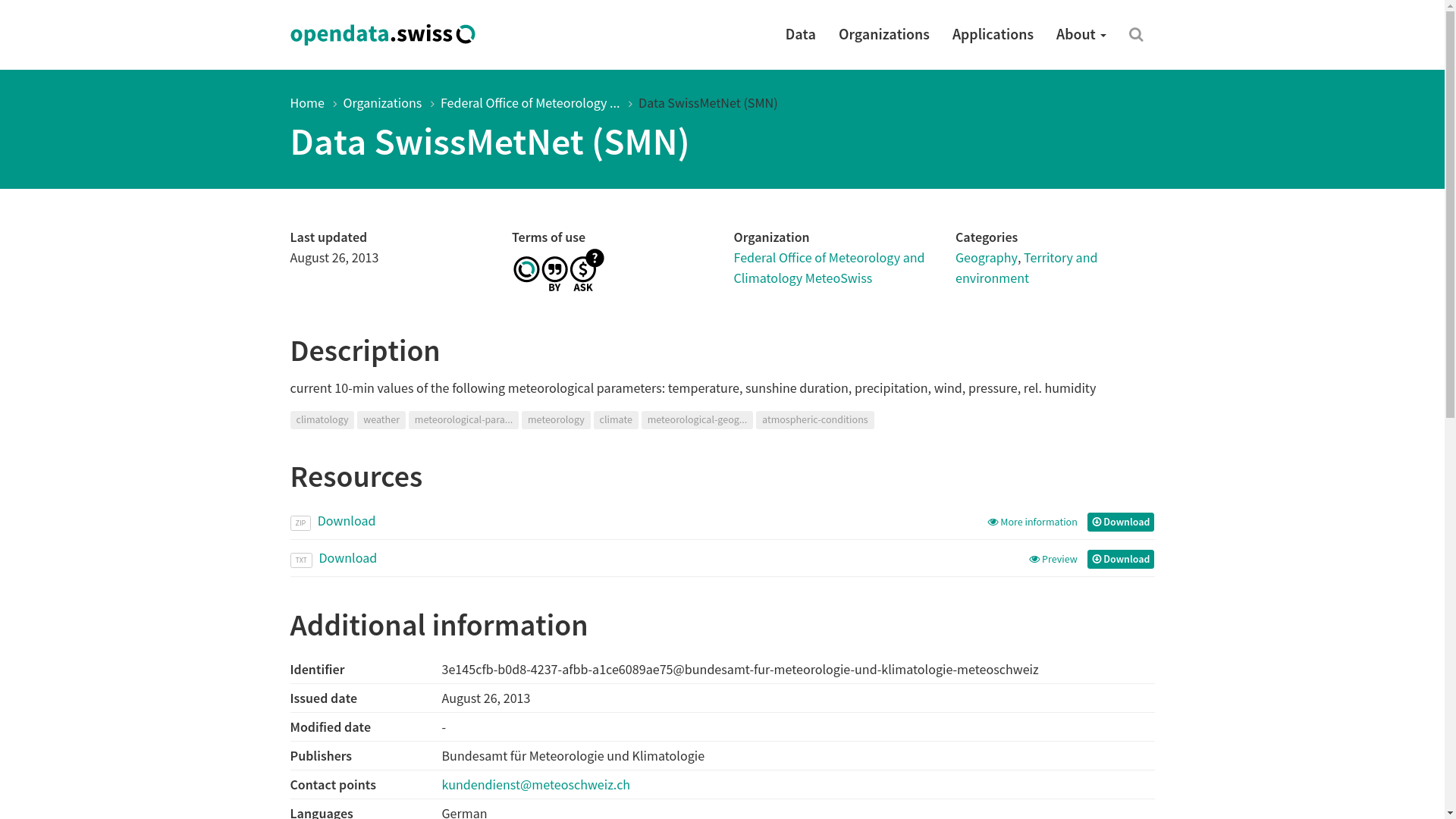
–Screenshot of opendata.swiss
They also host an important dialogue, serving to illustrate the challenges of publishing and reusing complex data, such as geographic data (“geodata”).
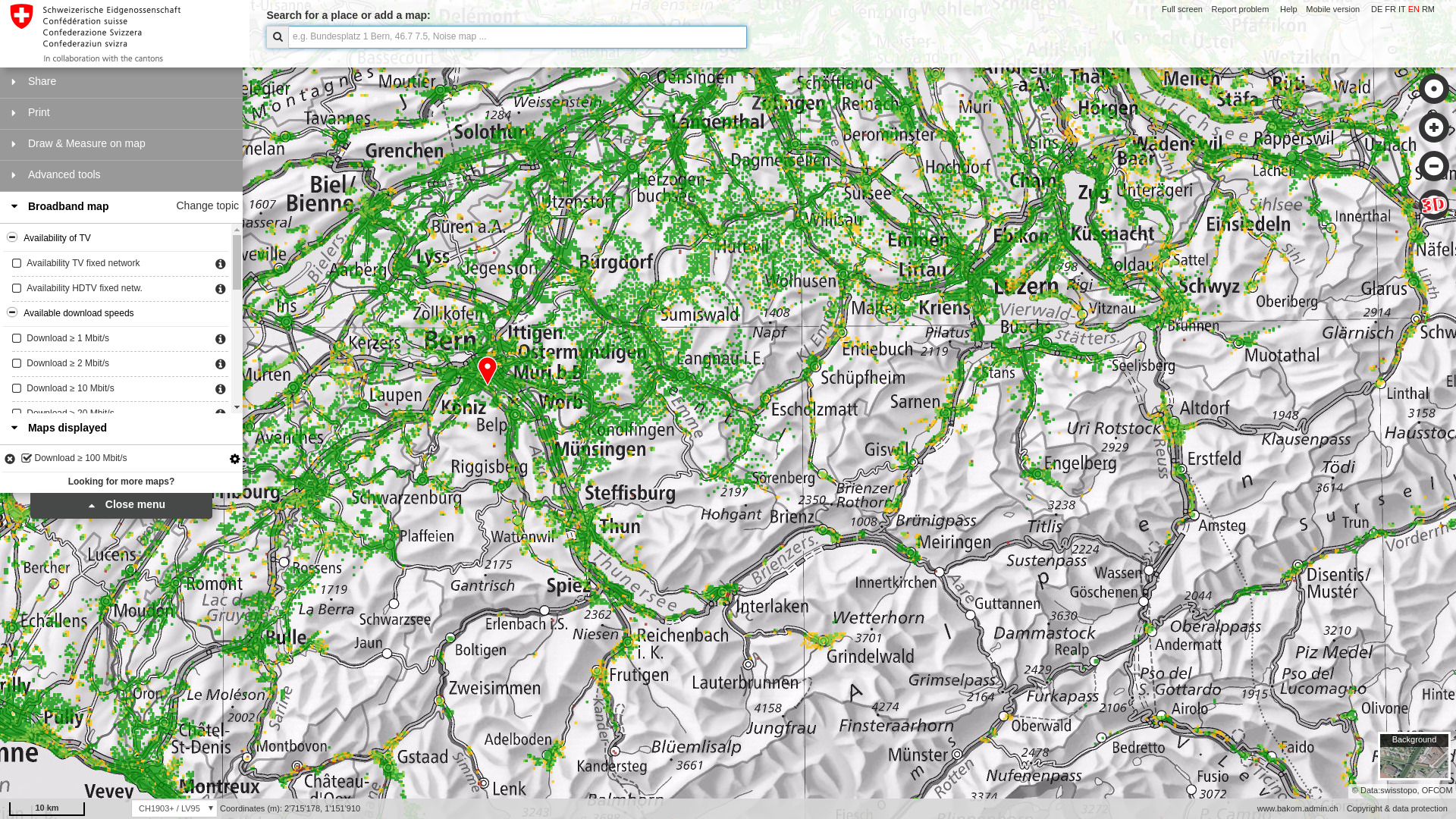
–Screenshot of map.geo.admin.ch
It is important to understand the Terms of use, both to be able to negotiate the various limitations and responsibilities placed on data reuse, as well as to consider the possible conditions under which future datasets are accessible.

–Screenshot of opendata.swiss
Note that these Terms (Nutzungsbedingungen), while similar in form to the Creative Commons levels, are not the same as Licenses. These are often applied to open data internationally, providing firmer legal grounding for further use and support. See Open Licenses Service for examples.
Data authorship, protection, and general rights of data producers and users are in Switzerland currently undergoing intense development, and are targets of legal scrutiny and debate. Stay tuned!
Community
From the activity described above, partly an outcome of large international movements affecting all fields of business, academic and the civic sphere, partly the hard work of local changemakers.
The result is fertile ground for an ‘ecosystem’ of open data providers and builders. Here are some pseudorandom examples of Swiss open data community projects:

![]()
… and many more.
Such communities endeavour to make data - already open data but in principle any data - even more usable and accessible to a wider public. One important vehicle is the Hackathon, a public event where data owners and users meet to work on brainstorming and prototyping possible new uses for data.
At such hackdays or hackathons we focus on the “Data” and the “Use” in the equation above, trying to solve the chicken-and-egg problem of having no reasons to make data available which nobody knows anything about. Visit hack.opendata.ch to learn about past and upcoming events.
Projects like the ones pictured above are sometimes made from scraped data, like the Open Budgets project which started by extracting data from a multi-hundred-page PDF. Others use official data sources, sometimes in inventive ways. Yet others rely on scraping the web, using platforms like morph.io, or crowdsourcing their data.
Leading projects use a combination of all possible methods to pool together interesting data.

–Screenshot of OpenCorporates
In each case, understanding and using such projects - as well as creating new ones - requires special competencies, a fundamental one is the ability to think critically with abstract, factual knowledge. Data literacy means being an active user of data, being aware of possible “bugs” in the facts and opinions of others - ultimately the ability to base one’s own decisions on verifiable evidence.
![]()
There are several projects in Switzerland to create better educational material and knowledge bases, e.g. for government employees (OGD Handbook) or for civic society (schoolofdata.ch). For more background see Defining Data Literacy at schoolofdata.org, an international organization which is behind a variety of data literacy projects.

– From R survey responses, School of Data on GitHub
Hands-on
In the last part of the introductory lecture, we collected ideas and discussed how to get to the data in a number of interesting scenarios. We will continue next week with a run down of the mechanisms for using and publishing open data in the R environment.
Links from our group discussion:
Open Street Maps: wie funktioniert das?
- http://wiki.openstreetmap.org/wiki/How_to_contribute
- http://overpass-turbo.osm.ch/
- http://umap.osm.ch/
- https://map.geo.admin.ch
Adressdaten mit Branchenverzeichnis (neue Firmen in der Branche)
- https://opencorporates.com/
- https://index.okfn.org/place/ch/companies/
- https://www.zefix.ch/de/search/entity/list/firm/1197913?name=datalets
- https://www.moneyhouse.ch/de/apiintegration
Steuerdaten/Einkommen auf Adressen/Geokoordinaten
- https://openspending.org/
- https://opendata.swiss/de/dataset?q=steuern
- https://index.okfn.org/place/ch/spending/
- http://opendata.iwi.unibe.ch/?orderBy=-date_publish
Swisstopo Karten zum herunterladen
- https://shop.swisstopo.admin.ch/de/products/maps/national/lk1000
- https://index.okfn.org/place/ch/map/
Bewegungsdaten (Passantenströme)
Ernährungsdaten ( z.B. zum Vergleich von Diäten)
2. Deep-dive
After an introductory session, we continued the second part of the course with a more profound discussion of the implications of open policies (internal and external) for organizations, and how the role of the Data Analyst is involved in the process of using and publishing open data.
First, I took an opportunity to mention one of the leading names for Open Government Data local to Bern, sharing a couple of key points from a presentation earlier that same day:

–Open Data rules the World! - Dr. Matthias Stürmer - Slideshare
Linked data
When explaining Open Data to the wider community especially, it often helps to use the 5-star deployment scheme from Tim Berners-Lee to introduce the different technical levels of openness. To illustrate:

–Image of mug obtainable at CaféPress
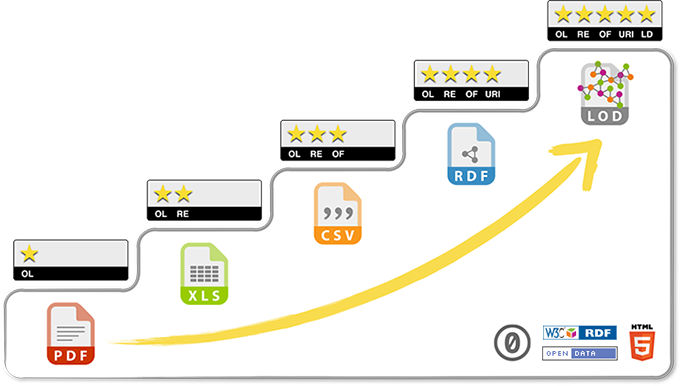
–A diagram from 5stardata.info makes for another nice visual summary
We focused our discussion on the difficulties of bridging the gap from one “star-level” to the next, agreeing that while formatting and publishing datasets online under the first 3 levels is releatively straightforward, the last two stars can be elusive to obtain.
An introduction to Linked Open Data (LOD) followed, where I explained the concepts of Ontologies, Triplestores, Intelligent agents, and some of the policies that make the worldwide LOD Cloud possible.
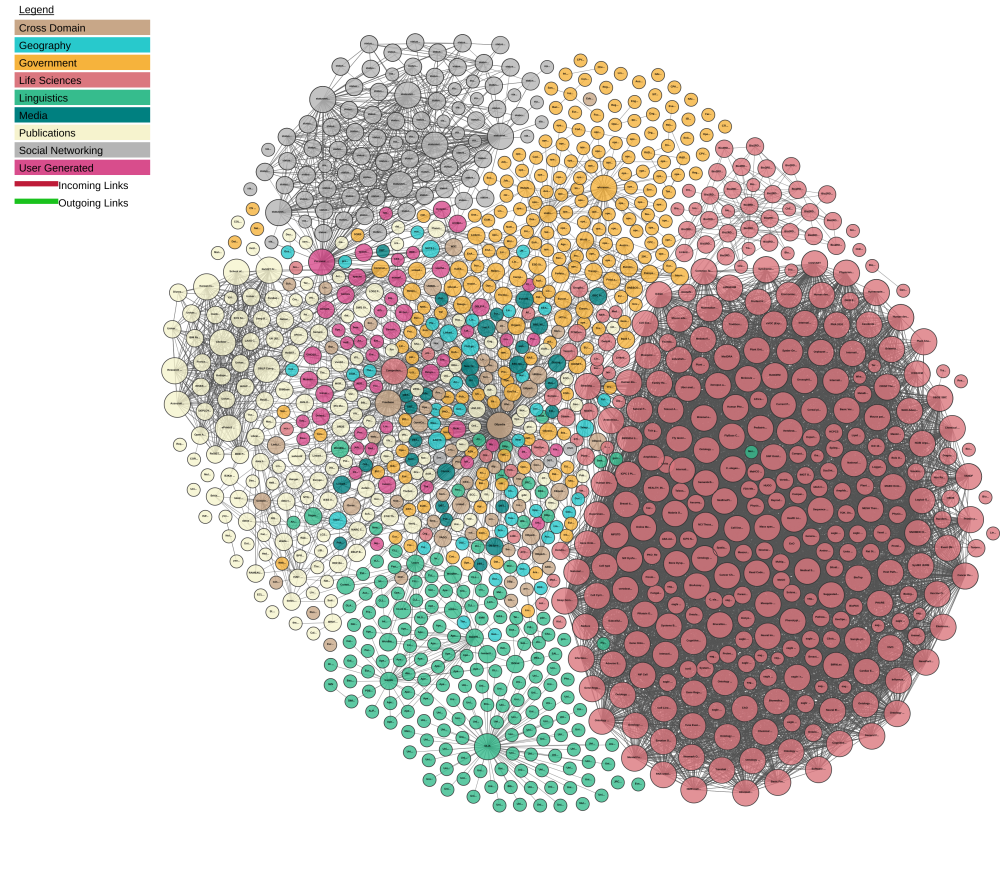
–Image via lod-cloud.net, to zoom in click here
{kind=link}
Finally, I briefly explained how SPARQL differs from SQL, and put some example queries in pseudocode on the whiteboard. Some of the students were aware of Enterprise Data Hubs, and I drew parallels between Linked Data and the kind of supports that exist in large organizations for aggregating diverse data sources.
Pro tip: there is support in the SPARQL package for making Linked Data queries from R. Check out this tutorial for example code.
Open principles
We proceeded to discuss some of the challenges and difficulties in implementing open data policies, often cited as reasons why data is not (quickly) shared and openly promoted. Again prompted by the morning lecture, I discussed each of the 10 Open Data Principles from the Sunlight Foundation in the USA.

–Via Open Data rules the World! - Dr. Matthias Stürmer - Slideshare
We talked about projects like Data Refuge which attempt to counteract some of these issues (#4 Access, and #9 Permanence, in this case), and used the WaybackMachine from the Internet Archive to surf Swiss government websites in the 90s.
Suggesting that the thousands of open data portals serve to promote these causes and overcome the challenges, we dived into the technical operations of open data portals.
Building on last week’s example, we looked at the way datasets can be explored with online interfaces such as STAT-TAB, which can be used to explore the data cubes of the Federal Statistical Office.
We also quickly looked at Google’s Public Data project:
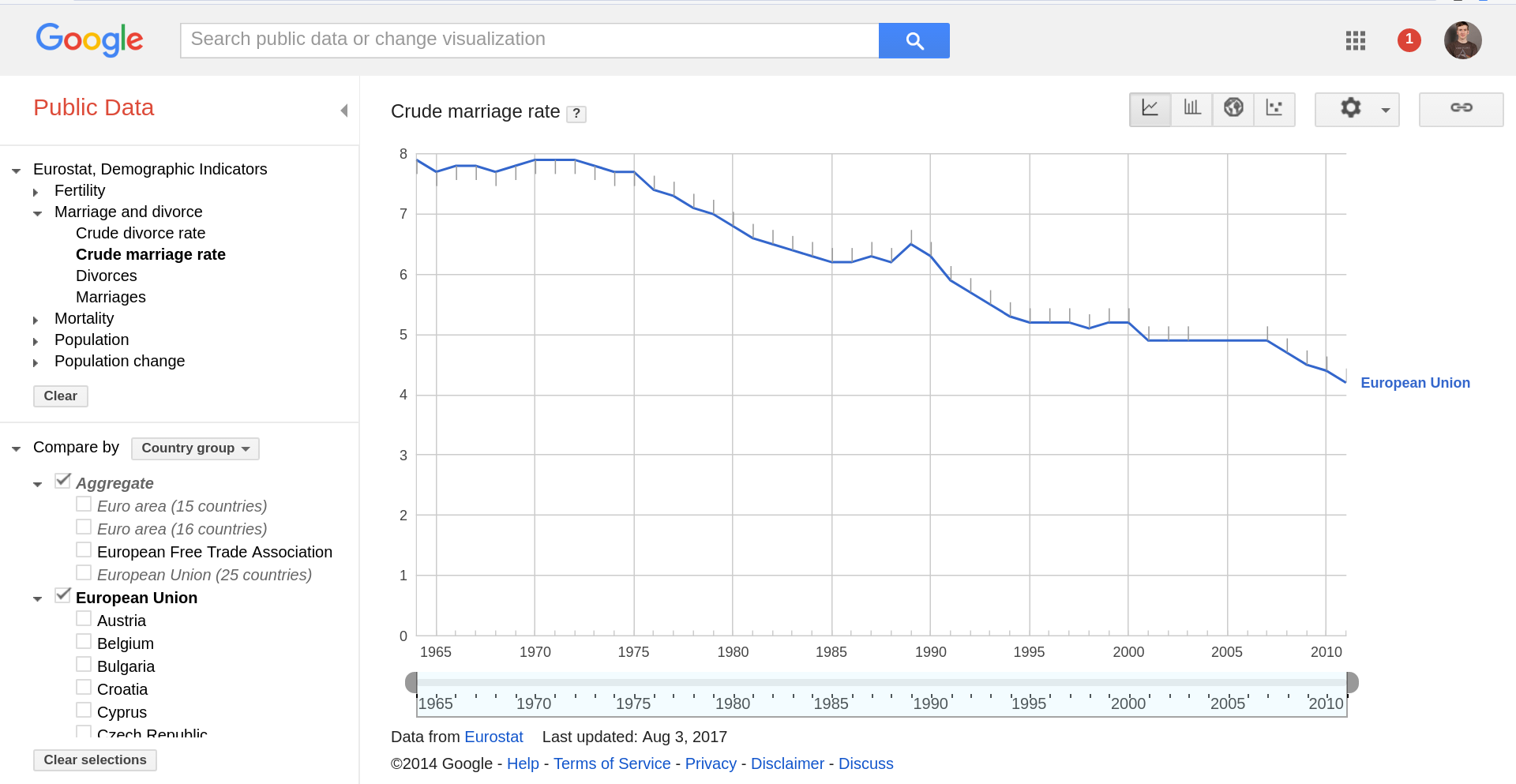
And contrasted these with the tools built into CKAN, the world’s most popular open data portal, the engine behind opendata.swiss.

–An ‘instant’ online chart from the Arbeitslosenquote dataset.
These interfaces, while more basic and harder for the “public” to use than a custom visualization like we looked at in part 1, make good on the promise of universal basic data access and should be further promoted.
Remember to use the “I have developed an application” (Ich habe eine Anwendung entwickelt) button if you develop a project with open data - the community and the data providers will want to hear about it!
One more use case for open data that we talked about was the Internet of Things, and I briefly illustrated my work with the Open Network Infrastructure Association this year on making use of open sensor data based on some groundbreaking new standards.
Pro tip: there is a handy R package for CKAN, which allows you to work with any CKAN instance. Try this sample code (download link) to get some fresh data directly from opendata.swiss:
install.packages("ckanr")
library('ckanr')
# Initialise the CKAN library with a remote portal
ckanr_setup(url = "https://opendata.swiss")
# Run a search to get some data packages
x <- package_search(q = 'name:arbeitslosenquote', rows = 2)
# Note that on the Swiss server the titles are multilingual
x$results[[1]]$title$de
# Get the URL of the first resource in the first package
tsv_url <- x$results[[1]]$resources[[1]]$url
# Download the remote (Tab Separated Values) data file
# ..and parse it in one step
raw_data <- read.csv(tsv_url, header=T, sep="\t")
# Draw a simple plot of the first and second column
plot(raw_data[,2], raw_data[,1], type="b")
Publishing steps
In the last part of the workshop we looked at the process behind the scenes of open data, and discuss the role of the Data Provider, which - under various titles - exists in every organization. Applying the structure of the OGD Handbook, we covered each step of the way which leads to the publication of the datasets we have been looking at. Namely:
- Identify
- Prepare
- Publish
- Support
The class was asked to work on a Data Inventory together, identifying datasets relevant to two more of the topic areas proposed in our brainstorm last week: “Preisentwicklung der Haus/Wohnungspreise” - data about trends in housing prices - and “Was gibt es öffentlich an persönlichen daten einsehbar?” - data about what kind of personal information is discoverable online.
Using Internet research and group discussion, a number of starting points were compiled which we then looked at all together. Through this several questions emerged which gave us new perspectives on the topic, and let us clarify various questions in how the process of opening government data actually worked.

We illustrated how open data is added to CKAN sites such as opendata.swiss using (the legacy interface to) DataHub.io.
Data packages
Finally, to complete the dots, we refocused on the R programming language, and discussed the concept of Data Packages, which are used to ease access to open datasets by the activist community. This standard translates well to hosting data inside R packages. The datasets library provides 108 datasets, such as swiss, which can be quickly used inside the R environment - only these provides data (frames) and not (just) tools.
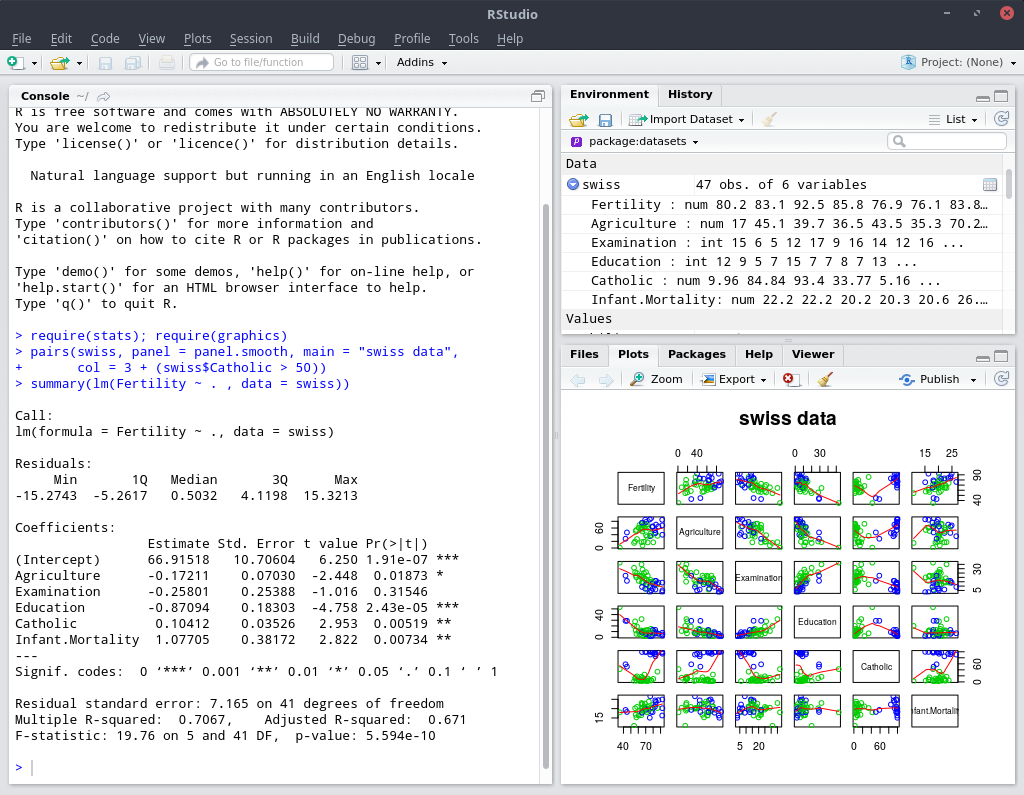
There are a couple of tutorials, such as External data by Hadley Wickham, to help you get started with writing your own R packages. I suggested to the class that as a take-home exercise, they could try writing their own R data packages, and sharing them with the study group.
We closed the workshop with a group discussion of the principles, opportunities and challenges involved. Asking “Who pays for the church bells?”, which reminded us that our session was almost over, I argued that open data provides certain value, but for now is not essential to most ‘business as usual’.

My argument for joining the practitioner community, supporting the cause, or just publishing data is simply: “You are not alone”. Many of the barriers we see between disciplines and organizations, owners and users, experts and non-experts, are quite arbitrary - and questionable. Data science is becoming a fundamental instrument to progress in our society, and I hope that open (government) data will continue to be a positive way to get support and share best practices with a wider community of data analysts and producers.
Finally, I encouraged the group to consider publish their future projects with openness principles, even if not immediately as open data, since the core tenants we have been discussing - clear attribution of sources, utilization of open standards, transparent record-keeping, shared ownership, and positive feedback loops - are universal.
Acknowledgements
Many thanks once again to the Bern University of Applied Sciences - to Prof. Dr. Arno Schmidhauser, Dr. Oliver Hümbelin and Andrea Moser especially, for generously supporting my involvement in the Certificate of Advance Studies - and to the attentive and encouraging group of students whom I wish all the best in the continuation of their studies and further application of data and knowledge.
– Oleg Lavrovsky, August 2017

This work is licensed under a Creative Commons Attribution 4.0 International License.