Haven’t been around for a while - happy to be back with a brainstorming question for our community:
We are currently setting up an awareness campaign around the role and value of data. We recently came up with the idea to let people donate their personal data. E.g. their voice to the open voice Mozilla project (https://voice.mozilla.org).
Do you know of any similar projects that would allow to donate personal data for a greater good?
Open & Thankful Wishes!
ps: We’re also pondering about how to set up the data collection in a secure and open-source way. If you have any tipps and tricks in this regard - also very welcome!
Thanks alot for posting your question here. I’m glad to see some interesting responses on Twitter…
And a somewhat tongue-in-cheek response from me…
In seriousness, I am cautious about the suggestion that our association or even the open data community is supposedly „collecting“ personal data. We should help people to take ownership, and contribute data directly to causes. Donating your data to the commons is akin to a blood donation drive, and you want to make sure it gets to people in need. But let’s not dice semantics. Give me more context, I would be share any best practices I know in the area, take the starting point and research this more. In other words, a good data café, like a good hackathon, should put the user needs first, and channel the data second.
Upon further thought, I realised my reply was not overly constructive. But who wants the loose bits and bytes off of my hard-drive, except spammers, stalkers and pirates? And how do you define greater good?
Driving knowledge and value from today’s mountains of data also brings policies related to ethics, privacy, security, intellectual property, and liability to the forefront, as the main concern on the agenda of policy makers. To help Big Data deliver its societal promises will require revised principles of monitoring and transparency, thus new types of expertise and institutions.
– Big Data for the Greater Good, Vincent Charles and Ali Emrouznejad, 2018
Fair enough. In this sense, the Mozilla project you mentioned has admirable aims - and you could even argue that high quality open voice data can save lives in certain emergencies. There is a whole realm of similar Machine learning datasets which are more or less openly collected and published. If you look at Citizen Science, you’re only a couple of searches away from lots ofdata-givingopportunities.
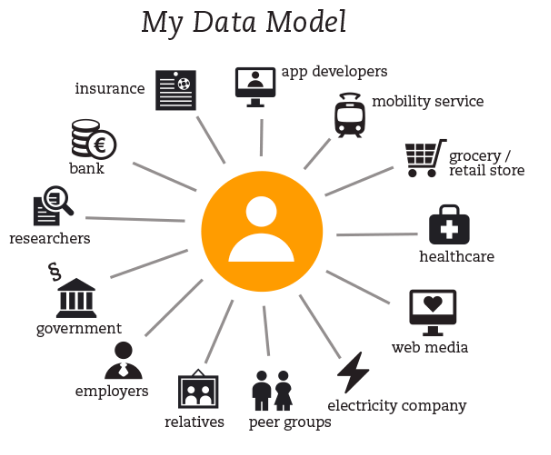
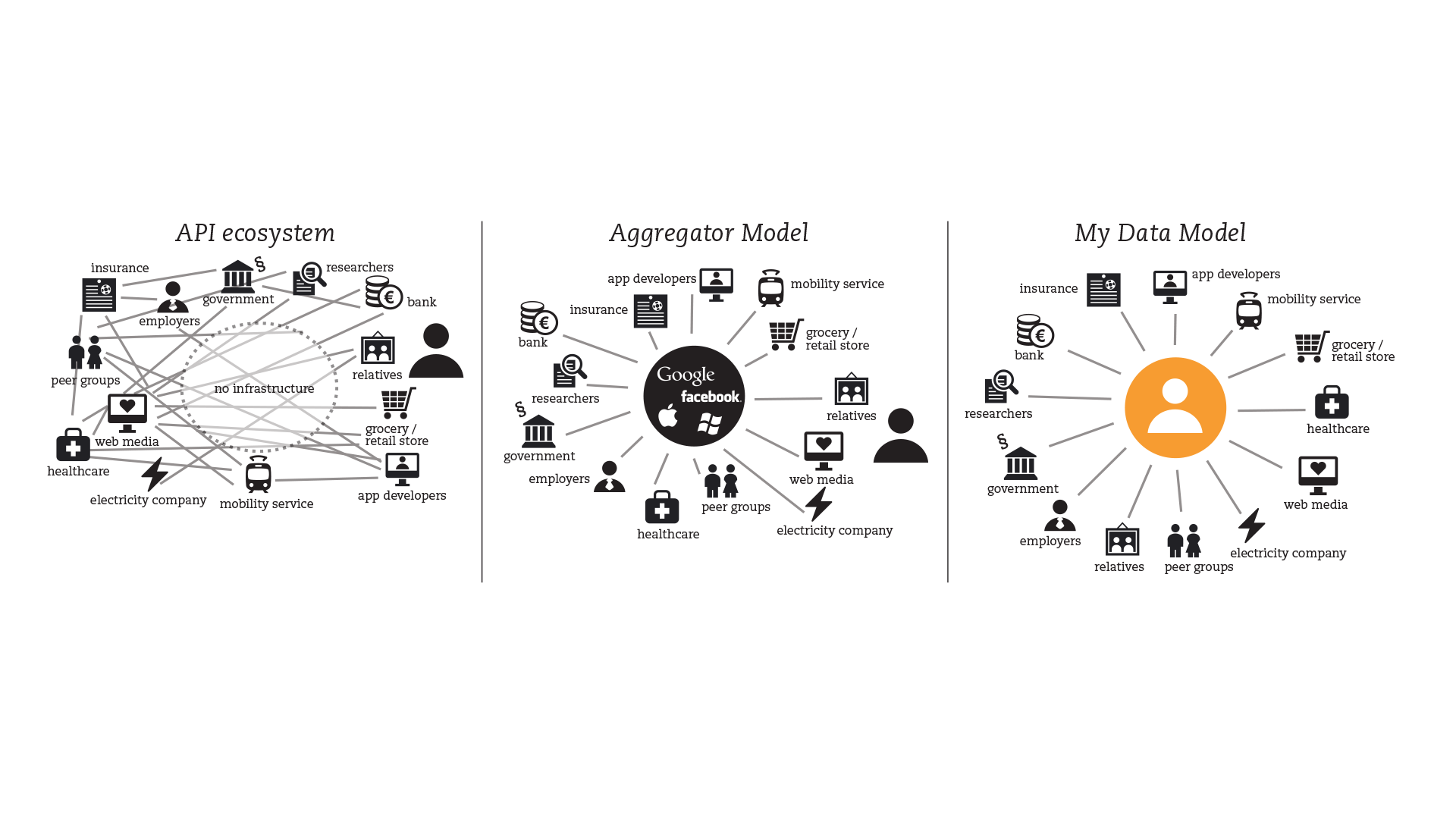
Speaking of research, I remembered this infographic from the MyData report by Poikola, Antti, Kai Kuikkaniemi, and Harri Honko, as potentially helpful to orient the discussion. They outline a number of scenarios and use cases in their report. But they did not (at least not at the time, 2015) address the question of donation.
The idea of donating the data of my electricity bill or insurance report at first glance seems preposterous. I don’t think “greater good” is strictly limited to health, or academics, but the relationship of societal benefit to personal data seems to be one of those deviously hard to pinpoint things, like the notion of social development to personal freedom. A more recent paper, Psychology of Personal Data Donation [summary, preprint, raw data] by Anya Skatova and James Goulding, explores the motivations and modes of giving data:
Donating personal data, similar to the way we donate blood, could become a new act of emerging digital economy prosocial behaviour. If ways can be found to encourage and enable individuals to donate their ‘digital footprint’ for academic research, this could contribute to knowledge in many domains. Prosocial behaviours are a common and valuable part of society, and data donation would likely encompass the generic features of these prosocial behaviours.
So if we flow with this metaphor and look at the guidance that people considering becoming a donor get, for example here…
…(great website, by the way) - there are basic things everyone needs to be informed about, like their blood type, the various kinds of donations possible, and what measures are taken to ensure safety and reliability along the way. In the data world, we urgently need this kind of guidance - before our data causes more harm than good. For example, here is some quality guidance (with my highlighting to draw attention to several universal concerns of data-gatherers) from the openSNP FAQ: What should I consider while creating a new phenotype?
Use a reasonable name for your characteristic. Don’t make it too long, but at the same time make sure that people get the general idea of what you want to know.
You should also make sure that the same phenotype is not already available in the openSNP-database. As soon as you start writing your characteristics name openSNP will try to auto-complete what you are writing. This should reduce duplicate phenotypes, so if you are about to enter “eye-colour” you will get a suggestions for the already available “eye-color” (Sorry, we can’t solve the AE / BE issue here).
Write a description about the characteristic you are interested in. Give users some words why this is interesting. Maybe add what research has been done so far on this phenotype. Links to further web-resources and/or Wikipedia might also be a good idea. If you already have suggestions which different answers might apply to this phenotype: List them in the description.
Enter your own variation: The last field, “variation” is meant to carry your own variation for this phenotype. Don’t enter all possible answers (You can list those in the description). Other users can easily add their own variation and take your suggestions from the description or - if you forgot to list a possible answer - give completely new answers.
As Rufus Pollock said in his 2016 Helsinki talk, My Data and Open Data are two sides of the same coin. There’s lots of work to be done, and I look forward to collaborating with you here @Nikki In the meantime, here are a couple of stops out there where we could all shed a few spare bytes:
WikiRate is a community of collaborative researchers; anyone can contribute. By bringing together diverse minds to design, develop, discuss, hone, populate and share free and open data about corporate performance, we are enabling the feedback systems necessary for a sustainable economy.
Thank you for volunteering to help the local communities and the Aid Organisations responding to this crisis by providing updated map data for them. Like you, we want to help as quickly as possible, and there is a real sense of urgency in what we do. But, the reason the Aid Organisations depend on us for map data is because we take time to make sure that what we produce is useful and meets their needs. We need you to take care too. Although it will delay you starting to update the map we need you to understand how and what to map fully before you start. Please do not rush in and start mapping without watching or reading some of the tutorials available first. It takes us much longer to clean up mistakes in mapping than it does to create them, and they may cause a care worker to have doubts about the dependability of the maps we produce.
Very very exciting to read about all these inspirational papers and projects. Thank you so much Oleg! It’s obvious to me that there’s a great potential and it feels like we should set up a data donation campaign soon!

{kind=link}